一、主从复制搭建方法参考
MySQL5.6数据库主从(Master/Slave)同步安装与配置详解请参考:
http://www.gzbifang.com/newsshow.php?id=270
二、Mysql 主从复制的常用拓扑结构
2.1、一主一从
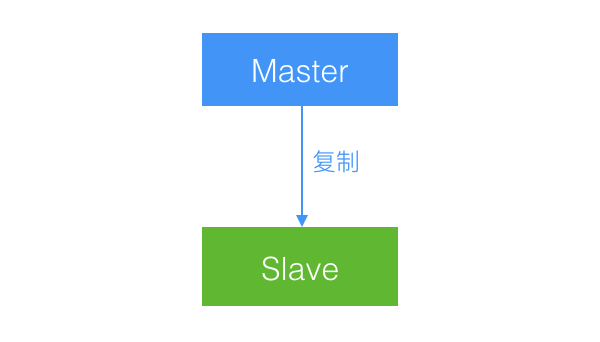
是最基础的复制结构,用来分担之前单台数据库服务器的压力,可以进行读写分离。
2.2、一主多从
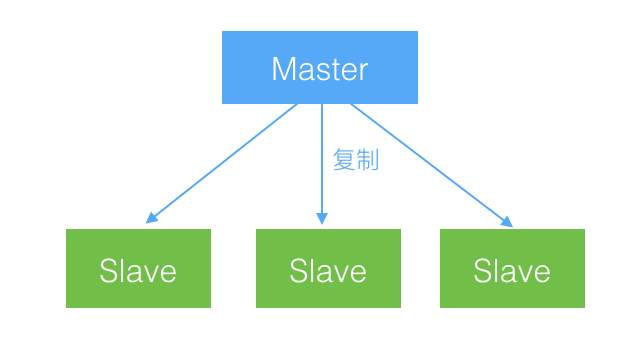
一台 Slave 承受不住读请求压力时,可以添加多台,进行负载均衡,分散读压力。
还可以对多台 Slave 进行分工,服务于不同的系统,例如一部分 Slave 负责网站前台的读请求,另一部分 Slave 负责后台统计系统的请求。
因为不同系统的查询需求不同,对 Slave 分工后,可以创建不同的索引,使其更好的服务于目标系统。
2.3、双主复制
Master 存在下线的可能,例如故障或者维护,需要把 Slave 切换为 Master。
在原来的 Master 恢复可用后,由于其数据已经不是最新的了,不能再做主,需要做为 Slave 添加进来。
那么就需要对其重新搭建复制环境,需要耗费一定的工作量。
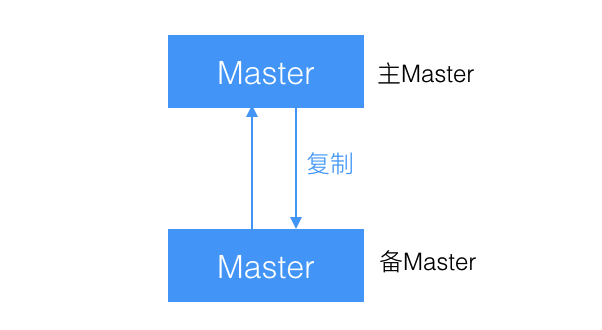
双主结构就是用来解决这个问题的,互相将对方作为自己的 Master,自己作为对方的 Slave 来进行复制,但对外来讲,还是一个主和一个从。
当 主Master 下线时,备Master 切换为 主Master,当原来的 主Master 上线后,因为他记录了自己当前复制到对方的什么位置了,就会自动从之前的位置开始重新复制,不需要人为地干预,大大提升了效率。
2.4、级联复制
当直接从属于 Master 的 Slave 过多时,连到 Master 的 Slave IO 线程就比较多,对 Master 的压力是很大的。
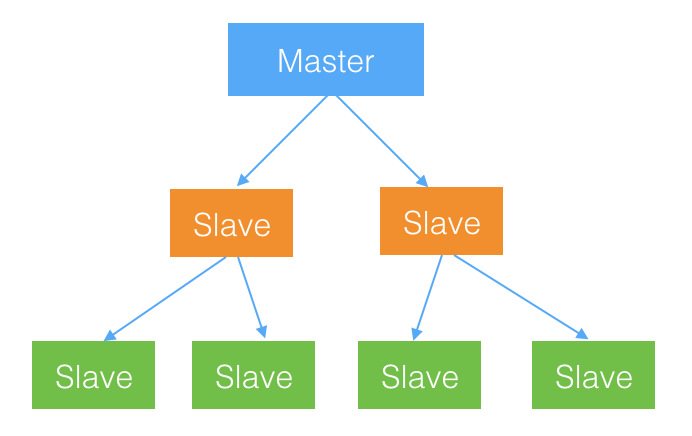
级联结构就是通过减少直接从属于 Master 的 Slave 数量,减轻 Master 的压力,分散复制请求,从而提高整体的复制效率。
2.5、双主级联
级联复制结构解决了 Slave 过多导致的瓶颈问题,但还是有单主结构中切换主时的维护问题。
那么为了解决这个问题,就可以加入上面的双主结构。
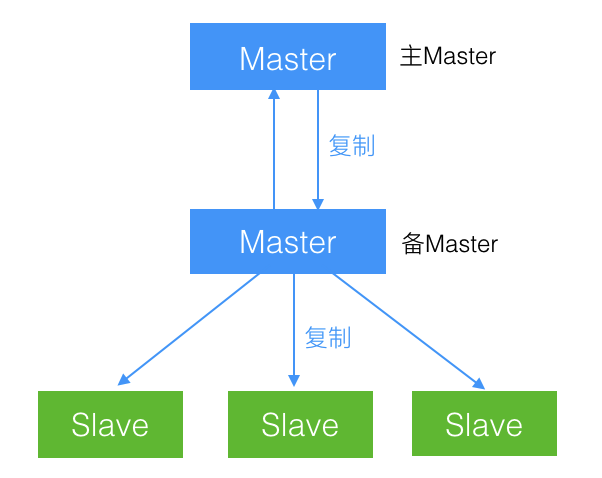
在必要时,可以再对 Slaves 进行分级。
Mysql 的复制结构有很多种方式,复制的最大问题是数据延时,选择复制结构时需要根据自己的具体情况,并评估好目标结构的延时对系统的影响。
三、Mysql 主从复制过程及原理
3.1、Binary Log 简单介绍
因为Binlog dump 线程操作的文件是bin-log 日志文件,并且实现主从复制在主服务器上主要依靠bin-log日志文件,所以我们简单介绍一下bin-log日志文件。
3.2、原理
MySQL的Replication(英文为复制)是一个多MySQL数据库做主从同步的方案,特点是异步复制,广泛用在各种对MySQL有更高性能、更高可靠性要求的场合。与之对应的是另一个同步技术是MySQL Cluster,但因为MySQL Cluster配置比较复杂,所以使用者较少。
MySQL Replication 就是从服务器拉取主服务器上的 二进制日志文件,然后再将日志文件解析成相应的SQL语句在从服务器上重新执行一遍主服务器的操作,通过这种方式来保证数据的一致性。
MySQL的Replication是一个异步复制的过程(mysql5.1.7以上版本分为异步复制和半同步两种模式),它是从一个Mysql instance(instance英文为实例)(我们称之为Master)复制到另一个Mysql instance(我们称之slave)。
3.3、三个线程
在master与slave之间实现整个复制过程主要由三个线程来完成:
1、Slave SQL thread线程,在slave端 2、Slave I/O thread线程,在slave端 3、Binlog dump thread线程(也可称为IO线程),在master端 注意:如果一台主服务器配两台从服务器那主服务器上就会有两个Binlog dump 线程,而每个从服务器上各自有两个线程。
要实现MySQL的Replication,首先必须打开master端的binlog (mysql-bin.xxxxxx)日志功能,否则无法实现mysql的主从复制。因为mysql的整个主从复制过程实际上就是:slave端从master端获取binlog日志,然后再在自己身上完全顺序的执行该日志中所记录的各种SQL操作。有关具体如何开启mysql的binlog日志功能,请大家自己在网上搜。
3.4、主从复制流程
MySQL主从复制的基本交互过程,如下:
1、slave端的IO线程连接上master端,并请求从指定binlog日志文件的指定pos节点位置(或者从最开始的日志)开始复制之后的日志内容。
2、master端在接收到来自slave端的IO线程请求后,通知负责复制进程的IO线程,根据slave端IO线程的请求信息,读取指定binlog日志指定pos节点位置之后的日志信息,然后返回给slave端的IO线程。该返回信息中除了binlog日志所包含的信息之外,还包括本次返回的信息在master端的binlog文件名以及在该binlog日志中的pos节点位置。
3、slave端的IO线程在接收到master端IO返回的信息后,将接收到的binlog日志内容依次写入到slave端的relaylog文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的master端的binlog文件名和pos节点位置记录到master-info(该文件存slave端)文件中,以便在下一次读取的时候能够清楚的告诉master"我需要从哪个binlog文件的哪个pos节点位置开始,请把此节点以后的日志内容发给我"。
4、slave端的SQL线程在检测到relaylog文件中新增内容后,会马上解析该log文件中的内容。然后还原成在master端真实执行的那些SQL语句,并在自身按顺丰依次执行这些SQL语句。这样,实际上就是在master端和slave端执行了同样的SQL语句,所以master端和slave端的数据完全一样的。
以上mysql主从复制交互过程比较拗口,理解起来也比较麻烦,我简化了该交互过程。如下:
1、master在执行sql之后,记录二进制log文件(bin-log)。
2、slave连接master,并从master获取binlog,存于本地relay-log中,然后从上次记住的位置起执行SQL语句,一旦遇到错误则停止同步。
从以上mysql的Replication原理可以看出:
-
主从间的数据库不是实时同步,就算网络连接正常,也存在瞬间主从数据不一致的情况。
-
如果主从的网络断开,则从库会在网络恢复正常后,批量进行同步。
-
如果对从库进行修改数据,那么如果此时从库正在在执行主库的bin-log时,则会出现错误而停止同步,这个是很危险的操作。所以一般情况下,我们要非常小心的修改从库上的数据。
-
一个衍生的配置是双主、互为主从配置,只要双方的修改不冲突,则可以工作良好。
-
如果需要多主库的话,可以用环形配置,这样任意一个节点的修改都可以同步到所有节点。
3.5、整体过程就是:
MySQL 复制基于主服务器在二进制日志中跟踪所有对数据库的更改(更新、删除等等)。每个从服务器从主服务器接收主服务器已经记录到其二进制日志的保存的更新,以便从服务器可以对其数据拷贝执行相同的更新。
将主服务器的数据拷贝到从服务器的一个途径是使用LOAD DATA FROM MASTER语句。请注意LOAD DATA FROM MASTER目前只在所有表使用MyISAM存储引擎的主服务器上工作。并且,该语句将获得全局读锁定。
MySQL 使用3个线程来执行复制功能,其中1个在主服务器上,另两个在从服务器上。当发出START SLAVE时,从服务器创建一个I/O线程,以连接主服务器并让它发送记录在其二进制日志中的语句。
主服务器创建一个线程,即I/O线程,将二进制日志中的内容发送到从服务器。该线程可以识别为主服务器上SHOW PROCESSLIST的输出中的Binlog Dump线程。
从服务器I/O线程读取主服务器Binlog Dump线程发送的内容并将该数据拷贝到从服务器数据目录中的本地文件中,即中继日志。
第3个线程是SQL线程,是从服务器创建用于读取中继日志并执行日志中包含的更新。
有多个从服务器的主服务器创建为每个当前连接的从服务器创建一个线程;每个从服务器有自己的I/O和SQL线程。
四、MySQL支持的复制类型及其优缺点
bin-log 日志文件有两种格式,一种是Statement-Based,另一种是Row-Based。
(1):基于语句的复制(Statement-Based): 在主服务器上执行的SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。 一旦发现没法精确复制时,会自动选着基于行的复制。
(2):基于行的复制(Row-Based):把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从mysql5.0开始支持
(3):混合类型的复制: 默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
4.1、Statement-Based优点和缺点分析
优点
-
bin-log日志包含了描述数据库操作的事件,但是这些事件包含的情况只是对数据库进行改变的操作,例如 insert、update、create、delete等操作。相反对于select、desc等类似的操作并不会去记录,并且它记录的是语句,所以相对于Row-Based来说这样会占用更少的存储空间。
-
因为bin-log日志文件记录了所有的改变数据库的语句,所以此文件可以作为以后的数据库的审核依据
缺点
- 不安全,并不是所有的改变数据的语句都会被记录复制。任何的非确定性的行为都是很难被记录复制的。
例如:对于delete 或者update语句,如果使用了limit但是并没有 order by ,这就属于非确定性的语句,就不会被记录
-
对于没有索引条件的update语句,必须锁定更多的数据,降低了数据库的性能。
-
insert……select 语句同样也需要锁定大量的数据,对数据库的性能有所损耗。
获取更详细的信息可以参考官方文档——Statement-Based的优点和缺点
4.2、Row-Based优点和缺点分析
优点
-
所有的改变都会被复制,这是最安全的复制方式
-
对于 update、insert……select等语句锁定更少的行
-
此种方式和大多数的数据库系统一样,所以了解其他的系统的人员可以很容易的转到mysql
缺点
-
使用不方便,我们不能通过bin-log日志文件查看什么语句执行了,也无从知道在从服务器上接收到什么语句,我们只能看到什么数据改变了
-
因为记录的是数据,所以说bin-log日志文件占用的存储空间要比Statement-based大。
-
对于数据量大的操作其花费的时间有更长
获取更详细的信息可以参考官方文档——Row-Based的优点和缺点
bin-log日志文件默认的格式为Statement-Based,如果想改变其格式在开启服务的时候使用—binlog-format选项,其具体命令如下
mysqld_safe –user=msyql –binlog-format=格式 & 四、主服务器流程分析
4.1、主服务器线程 Binlog dump thread
Binlog dump 线程是当有从服务器连接的时候由主服务器创建,其大致工作过程经历如下几个阶段:
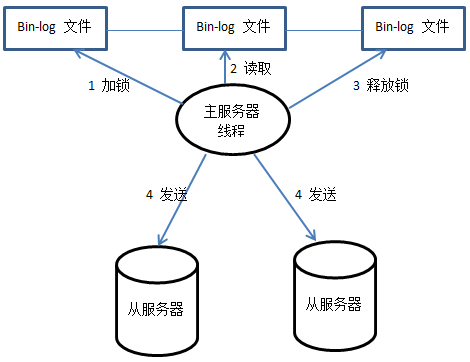
首先bin-log日志文件加锁,然后读取更新的操作,读取完毕以后将锁释放掉,最后将读取的记录发送给从服务器。
我们可以使用如下的命令来查看该线程的信息
mysql> SHOW PROCESSLIST\G 以我的系统为例,因为我这系统中是一台主服务器和两台从服务器,所以会列出两条Binlog dump线程的信息
*************************** 1. row *************************** Id: 2 User: repuser
Host: 192.168.144.131:41544 db: NULL Command: Binlog Dump
Time: 54
State: Master has sent all binlog to slave; waiting for binlog to be updated
Info: NULL *************************** 2. row *************************** Id: 3 User: repuser
Host: 192.168.144.132:40888 db: NULL Command: Binlog Dump
Time: 31
State: Master has sent all binlog to slave; waiting for binlog to be updated
Info: NULL 上述字段中的state字段会有以下几种状态:
1. Sending binlog event to slave
表示Binlog dump 线程已经读取完binlog日志中更新的event,现在正在发送给从服务器 2. Finished reading one binlog; switching to next binlog
表示Binlog dump 线程已经读取完一个binlog日志,现在正在打开下一个binlog日志读取来发送给从服务器 3. Master has sent all binlog to slave; waiting for binlog to be updated
这就是上面我们看到的state的值,表示Binlog dump 线程已经读取完所有的binlog日志文件,并且将其发送给了从服务器。现在处于空闲状态,正在等待读取有新的操作的binlog日志文件 4. Waiting to finalize termination
这个状态持续的很短暂,我们几乎看不到。当线程停止的时候显示此状态 上述几个状态就是一次主从复制过程中Binlog dump 线程所经历的状态,如果我们是在测试的环境中,上述1、2、4状态我们几乎是看不到的,因为它执行的很快。
在主从系统中主服务器上的一个主要的文件就是bin-log日志,该线程操作的文件也是此日志文件,因此这是我们需要在配置文件my.cnf 中打开bin-log日志的原因,使用此文件来记录我们的更新操作。
[mysqld] log-bin = mysql-bin server-id = 1 还有一点需要注意,在上面已经说过,但是在这里觉得有必要再重复一遍,就是有多少个从服务器连接主服务器上就有多少个Binlog dump 线程。
bin-log日志文件管理
对于bin-log日志文件,其默认的名称为 mysql-bin.xxxxxx。而且还有一个索引文件mysql-bin.index,其中记录了当前所有的bin-log日志文件。
对于新的主服务器只有一个bin-log日志文件 mysql-bin.000001。此时所有的操作都有这个文件来记录,如果我们想更换bin-log日志文件,可以使用如下命令
Mysql>flush logs; 此时会创建一个mysql-bin.000002文件来记录以后的操作。除了使用上述命令以外,当bin-log日志文件达到其最大值的时候也会产生新的bin-log日志文件
其文件最大值和文件名包括索引文件的名称可以使用 –max_binlog_size、–log-bin和—log-bin-index 选项来改变,具体命令如下
mysqld_safe –user=msyql –max_binlog_size=文件长度 –log-bin=新的日志文件名称 –log-bin-index=新索引文件名 & 对于主服务器来说,总起来一句话:主服务器针对于每一个从服务器都创建一个Binlog dump线程,用来读取bin-log日志中更新的操作将其发送给从服务器,发送完毕以后继续等待bin-log日志是否有更新。
五、从服务器流程分析
在主服务器探究这篇文章中我们提到过,在一次主从复制过程中需要用到三个线程:Binlog dump 线程、Slave I/O 线程和Slave SQL线程,其中Binlog dump 线程在主服务器上面,剩下的两个线程是在从服务器上面工作的。
这两个线程在从服务器上面的工作流程如下图所示:
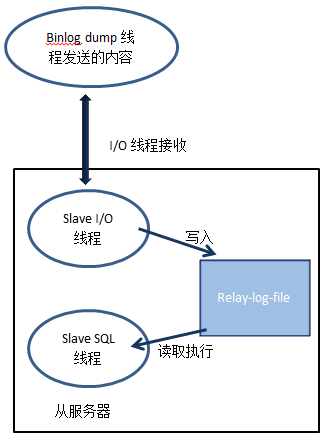
对于这两个线程随着从服务器开启slave而产生
mysql> START SLVAE; 然后使用
Mysql> SHOW SLAVE STATUS\G 查看这两个线程情况
…… Master_Log_File: mysql-bin.000003 Read_Master_Log_Pos: 1264 Relay_Log_File: localhost-relay-bin.000002 Relay_Log_Pos: 878 Relay_Master_Log_File: mysql-bin.000003 Slave_IO_Running: Yes Slave_SQL_Running: Yes
……
上面结果中的 Slave_IO_Running:Yes和Slave_SQL_Running:Yes表示这两个线程正在运行。
然后我们在从服务器上面使用命令
mysql> SHOW PROCESSLIAT\G 显示如下结果(记为 结果一)
*************************** 1. row *************************** Id: 22 User: system user
Host: db: NULL Command: Connect
Time: 4
State: Waiting for master to send event
Info: NULL *************************** 2. row *************************** Id: 23 User: system user
Host: db: NULL Command: Connect
Time: 4
State: Slave has read all relay log; waiting for the slave I/O thread to update it
Info: NULL
从State信息可以看出Id 22是I/O线程,正在等待主服务器发送更新的内容;Id 23是Slave SQL线程,已经读取了relay log 文件中所有更新的内容,正在等待I/O线程更新该文件。
使用命令停止slave机制
mysql> STOP SLVAE; 然后我们再次查看会发现结果如下
…… Master_Log_File: mysql-bin.000003 Read_Master_Log_Pos: 1264 Relay_Log_File: localhost-relay-bin.000002 Relay_Log_Pos: 878 Relay_Master_Log_File: mysql-bin.000003 Slave_IO_Running: No Slave_SQL_Running: No
……
说明这两个线程已经停止了运行。此时再次使用 SHOW PROCESSLIST\G命令,则没有结果显示
5.1、Slave I/O线程
Slave I/O 线程去连接主服务器的Binlog dump 线程并要求其发送binlog日志中记录的更新的操作,然后它将Binlog dump 线程发送的数据拷贝到从服务器上(也就是本地)的文件relay log中。
当然要查看此线程是否运行,除了上面介绍的方法,还可以使用
mysql> SHOW SLAVE LIKE 'Slave_running'; 这时如果出现下面的结果说明该线程正在运行
+-----------------+-------------------+ | Variable_name | Value |
+-----------------+-------------------+ | Slave_running | ON |
+-----------------+-------------------+ 在上述结果一中我们可以看到1.row即是Slave I/O线程的信息,其State: Waiting for master to send event 表示正在等待主服务器发送内容。当然State不止这一个值,它还有其它的值,下面列出了State的所有的值
1. Waiting for master update
在连接到主服务器之前的初始状态 2. Connecting to master
该线程正在连接主服务器,当然如果我们的网络环境优异的话,此状态我们几乎是看不到的 3. Checking master version 这个状态发生的时间也非常短暂,该状态在该线程和主服务器建立连接之后发生。 4. Registering slave on master 在主服务器上面注册从服务器,每当有新的从服务器连接进来以后都要在主服务器上面进行注册 5. Requesting binlog dump
向主服务器请求binlog日志的拷贝 6. Waiting to reconnect after a failed binlog dump request
如果5中失败,则该线程进入睡眠状态,此时State就是这个值,等待着去定期重新连接主服务器,那这个周期的大小可以通过CHANGE MASTER TO 来指定 7. Reconnecting after a failed binlog dump request
去重新连接主服务器 8. Waiting for master to send event
此值就是我们上述结果所显示的,正常情况下我们查看的时候一般都是这个值。其具体表示是这个线程已经和主服务器建立了连接,正在等待主服务器上的binlog 有更新,如果主服务器的Binlog dump线程一直是空闲的状态的话,那此线程会等待很长一段时间。当然也不是一直等待下去,如果时间达到了slave_net_timeout规定的时间,会发生等待超时的情况,在这种情况下I/O线程会重新去连接主服务器 9. Queueing master event to the relay log 该线程已经读取了Binlog dump线程发送的一个更新事件并且正在将其拷贝到relay log文件中 10. Waiting to reconnect after a failed master event read 当该线程读取Binlog dump 线程发送的更新事件失败时,该线程进入睡眠状态等待去重新连接主服务器,这个等待的时间默认是60秒,当然这个值也可以通过CHANGE MASTER TO来设置 11. Reconnecting after a failed master event read 该线程去重新连接主服务器,当连接成功以后,那这个State的值会改变为 Waiting for master to send event 12. Waiting for the Slave SQL thread to free enough relay log space relay log space的大小是通过relay_log_space_limit来设定的,随着relay logs变得越来越大所有的大小合起来会超过这个设定值。这时该线程会等待SQL线程释放足够的空间删除一些relay log文件 13. Waiting for slave mutex on exit 当线程停止的时候会短暂的出现该情况 以上就是State可能会出现的值,以及都是在什么情况下出现。
5.2、Slave SQL线程
Slave SQL线程是在从服务器上面创建的,主要负责读取由Slave I/O写的relay log文件并执行其中的事件。
在上述结果一中2.row即是Slave SQL线程的信息,同样有一个State表示该线程的当前状态。
下面也列出了State所有可能出现的情况。
1. Waiting for the next event in relay log 该状态是读取relay log之前的初始状态 2. Reading event from the relay log 该状态表示此线程已经在relay log中读取了一个事件准备执行 3. Making temp file 该状态表示此线程正在执行LOAD_DATA_INFILE并且正在创建一个临时文件来保存从服务器将要读取的数据 4. Slave has read all relay log; waiting for the slave I/O thread to update it 该线程已经处理完了relay log中的所有事件,现在正在等待slave I/O线程更新relay log文件 5. Waiting for slave mutex on exit 当线程停止的时候会短暂的出现该情况 上面是对从服务器上的两个线程的简单的介绍,在运行过程中我们会发现这两个线程都离不开的文件就是relay log文件,下面我们简单介绍一下relay log文件。
5.3、relay log文件
relay log 和 主服务器上的bin log很相似,都是一系列的文件,这些文件包括那些包含描述数据库改变的操作事件的文件和索引文件,这个索引文件是relay logs文件的名称集合。
relay log 文件和 bin log文件一样,也是二进制文件,不能直接查看,需要使用mysql自带工具mysqlbinlog查看。
] # mysqlbinlog mysql安装路径/data/relay-log文件
当然其索引文件的内容我们是可以直接使用 vim查看的。
对于relay logs 文件的名称的命名规则默认使用的是 host_name-relay-bin.nnnnnn,以我的系统来说,其文件名默认为localhost-relay-bin.000001。对于索引文件的命名规则为host_name-relay-bin.index,同样在我的系统中的名称为localhost-relay-bin.index。这两个名称是可以通过—relay-log 和 –relay-log-index来改变的,其使用方式如下:
mysqld_safe –user=mysql –relay-log=文件名 –relay-log-index=新索引文件名 & 在这里如果改变这两个名称的话,可能会引起'不能打开relay log'文件和'在初始化relay log 过程中不能发现目标log'等错误。这也算是mysql设计的一个bug,没有什么好的解决办法,如果我们不想使用默认的文件名称的话,唯一的办法就是我们可以预料到从服务器的主机名称可能在将来会发生改变,在开始初始化从服务器的时候就使用以上两个选项指定文件名,这样就可以使文件名不再依赖于服务器的主机名。
对于这些relay log文件并不是一直在增加的,当Slave SQL线程执行完一个relay log文件中所有的事件并且不再需要它的时候会把改relay log文件删除。由于是Slave SQL线程来做这些事情,所以也没有什么明确的规则来指定如何删除relay log文件
以上的所有内容大概描述了主从复制系统中从服务器的主要工作流程。
六、如何提高Mysql主从复制的效率?
MySQL的主从复制,实际上就是Master记录自己的执行日志binlog,然后发送给Slave,Slave解析日志并执行,来实现数据复制。对于复制效率,binlog的大小是非常重要的因素,因为它涉及了I/O和网络传输
主从复制涉及到了两端:master/slave,看下这两端可以如何优化
(1)master 端
master端有2个参数可以控制
Binlog_Do_DB : 设定哪些数据库需要记录Binlog
Binlog_Ignore_DB : 设定哪些数据库不要记录Binlog
这两项很重要,指定必要数据库,忽略不需要复制的数据库,可以减少binlog的大小,提高了I/O效率,加快网络传输。
但这两项也同样比较危险,需要谨慎使用,因为可能会有主从数据不一致和复制出错的风险。
因为MySQL判断是否须要复制某个Event,不是根据产生该Event的语句所在的数据库,而是根据执行时所在的默认数据库,也就是登录时指定的数据库,或运行"USE DATABASE"中所指定的数据库。
如果执行语句中明确指定了数据库名称,而这个数据库是被指定不记录Binlog的,那么这个语句在slave中执行时就会出错。
例如
garbage 库是被指定不记录日志的
product 库是指定要记录日志的 执行下面的语句
use product; delete from garbage.junk; delete语句会被发送给slave,但slave中没有garbage库,所以执行时报错,复制失败
(2)slave 端
slave端有6个参数可以控制
Replicate_Do_DB : 设定须要复制的数据库,多个DB用逗号分隔
Replicate_Ignore_DB : 设定可以忽略的数据库
Replicate_Do_Table : 设定须要复制的Table
Replicate_Ignore_Table : 设定可以忽略的Table
Replicate_Wild_Do_Table : 功能同Replicate_Do_Table,但可以带通配符来进行设置
Replicate_Wild_Ignore_Table : 功能同Replicate_Ig-nore_Table,可带通配符设置
slave端的配置优化效果要明显小于master端的,因为master端日志都写完了,日志也传过来了
但这几个参数可以帮助我们减少日志的应用量,因为设置了过滤,实际写入的sql数量变少了,slave端的复制也就加快了